2024. 1. 16. 14:24ㆍCS/데이터베이스
Transaction
해당 교재에서 트랜잭션은 ‘Single Logical Unit of Work’ 으로 규정하고 있습니다. 일상생활의 예를 들자면, 제가 다른 친구에게 돈을 송금할 때, DBMS 내부에서는 제 계좌의 돈을 차감 후 , 전달받는 친구 계좌의 돈을 증가 시키는 절차를 가집니다.
이러한 연산들은, 장애가 발생해도 처리가 가능해야 합니다. 돈을 송금하는 도중에 서비스에 장애가 발생해서 제 계좌의 돈만 차감된다면, 돈이 증발하는 꼴이 됩니다. 데이터베이스는 트랜잭션을 통해 작업의 원자성, 일관성, 고립성, 내구성을 보장합니다.
Basic Concept of Transaction
트랜잭션은 여러 값에 접근하여 값을 변경시키는 프로그램 실행의 단위입니다.
위에서 제시한 송금 시나리오를 의사코드로 작성해보겠습니다.

A -> B 에게 50 불을 송금하고 있습니다. 이러한 일련의 작업을 수행함에 있어서, 다뤄야 할 두가지 중요한 문제가 있습니다.
- 실패 ( HW failure, System crash)
- 동시성 문제 ( 만약 이런 트랜잭션들을 여러 클라이언트가 동시에 실행한다면? )
이렇듯, DBMS 는 ‘유의미한 데이터를 저장하는’ 데이터베이스를 관리해야 하기 때문에, 데이터의 손실을 최대한 막아야 합니다.
따라서 DBMS는 트랜잭션의 4가지 속성인 ACID를 정의하고, 해당 속성을 보장하기 위한 다양한 기능들을 내부적으로 적용합니다.
Atomicity (원자성)
모든 트랜잭션의 연산들은 DB에 적절하게 반영되던가, 반영되지 않아야 한다. (All or Not)
만약 3번 작업 이후, 6번 작업 이전에 데이터베이스가 fail 하게 된다면, 돈은 누구에게도 전송되지 않고, 잃어버린 상태가 됩니다. 이러한 상태를 inconsistent 한 database 상태라고 부르며, 결코 일어나서는 안되는 일 입니다.
DBMS 는 Atomicity 를 보장하며, Recovery System 이 담당합니다.
Consistency (일관성)
트랜잭션 이후 데이터들은 일관된 상태를 유지해야 한다. (즉, A와 B의 값이 변해선 안된다.)
트랜잭션이 실행될 때, 무조건 일관적인 데이터만 노출되어야 합니다. 예를 들면, A:200$, B:100$ 의 잔고를 가졌고, A가 B에게 50$을 송금할 때, A:150$, B:150$ 이나, A:200$, B:100$ 의 데이터만 노출되어야 합니다. (합이 300)
그렇지 않게 된다면 데이터의 일관성이 깨지고, 현실세계의 문제가 발생할 수 있습니다.DBMS는 Consistency 에 대해 책임을 지지 않습니다. 따라서, 개발자는 올바른 primary key, foreign key 등의 Integrity Constraints를 명시적으로 정의해야 합니다.
Isolation (고립성)
각 트랜잭션들은 다른 트랜잭션에 영향을 미치면 안됩니다. 즉, A 트랜잭션이 먼저 실행되나, B 트랜잭션이 먼저 실행되나, 결과값에 차이는 없어야 합니다. 그럼 “A를 수행한 뒤에 B가 수행되도록 강제할 수 있잖아! ” 를 궁금해 하실 수도 있겠습니다. 하지만 현재 컴퓨팅 자원은 멀티코어 프로그래밍이고, 멀티코어가 지원하는 동시성 혜택을 보기 위해서는 순서를 강제로 제한해서는 안되고, 각 트랜잭션은 고립된 환경에서 실행되는 것 처럼 보여야 합니다. 즉, 한 트랜잭션은 다른 트랜잭션에 영향을 미쳐서는 안됩니다. DBMS는 Concurrency Control System 을 통해, Isolation 을 보장합니다.
Durability (내구성)
한번 commit 된 내용은, DB에 영속적으로 저장되어야 합니다. SW나, HW가 실패해도, 트랜잭션이 완료된다면 영속적으로 저장되어야 합니다. 각 트랜잭션은 실패시 롤백이 가능합니다. 또한 한번 commit 시, 이미 실행된 연산에 관하여 undo 는 불가능 합니다. Durability 또한 recovry System을 이용하여 durability 를 보장합니다.
일관되지 않은 상태에도, 단계가 있습니다. 함께 알아보겠습니다.
Inconsistency Level
Attribute-level Inconsistency

각 트랜잭션 T1 과 T2는 따로 실행 시, 문제가 없는 것 같아 보입니다.
하지만 컴퓨팅 세계에서 문제는 언제나 여러 유저가 접근 할 때 발생합니다. 이번에는 T1, T2 트랜잭션을 두명의 유저가 동시에 실행한다고 가정하겠습니다.
두명의 유저가 트랜잭션을 각각 동시에 실행 시, 일어날 수 있는 결과는 두개가 됩니다. QTY의 값이 변동되었지만,
한 트랜잭션의 값만 적용 된 상태입니다. 이렇듯, Attribute 범위에서 발생하는 데이터의 Inconsistent 를, Attribute-level Inconsistency 라고 부릅니다.
Tuple-level Inconsistency

다음은 Tuple 에서 발생하는 Inconsistency 입니다.
T1 이 qty 의 값을 변경하는 연산을 수행하고,
T2가 동시에 같은 tuple 의 다른 attribute를 변경하는 연산을 수행할 시, T1의 변경이 적용되지 않은 상태를 T2 연산에서 읽을 수 있습니다.
Relation-level Inconsistency

다음은 더 높은 범위인 Relation 에서 발생할 수 있는 Inconsistency 입니다.
T1은 where 조건에 의해 price의 값을 변경합니다.
그 순간에 T2 연산 또한 where 조건에 의해 Sale의 값을 변경하게 됩니다.
이 순간, ID= 1233을 본다면 T1 에 의해 Price 가 400000으로 변경되어, T2의 where 조건을 만족하지만,
T2는 이미 해당 튜플의 값을 800000으로 인식하고 만족하지 않는 것으로 간주, 지나칠 수 있습니다.
이 현상 또한 Relation에서 일어날 수 있는 Inconsistency (비일관성) 입니다.
Transaction 의 절차
SQL 표준에서는 트랜잭션을 A sequence of operations treated as a unit 으로 정의하고 있습니다.
따라서 제일 첫번째 SQL문이 자동으로 Transaction의 시작이라고 할 수 있겠습니다.
Commit 을 호출시, 트랜잭션의 종료를 의미하고, Rollback을 호출 시, 트랜잭션의 취소를 의미합니다.
Autocommit 모드의 경우는 SQL 문장 하나 단위로 Transaction을 진행합니다.


트랜잭션의 예시입니다. 위 예시에서는, 3209 계좌의 잔고에서 500을 뺀 후에 3208 계좌에 500을 더하고,
journal 테이블에 기록을 남기는 모습을 보여줍니다. 즉, 송금을 진행하는 트랜잭션이라고 할 수 있겠습니다.
트랜잭션이 완료된 이후에는 Commit 을 통해 완료를 명시합니다. WORK는 보통 가독성 향상을 위해 사용합니다. (Optional)
DML의 경우, Commit, Rollback 으로 트랜잭션의 단계를 정의할 수 있음을 알 수 있었습니다.
DDL은 명령 하나하나가 트랜잭션으로 작동합니다. (테이블 생성, 테이블 drop 등)
System Crash로 부터의 안전성
이 부분은 다음 장에서 자세히 다루겠습니다.

해당 트랜잭션을 실행 중에, System Crash 가 발생하였다고 가정해봅시다.
DBMS 는 Atomicity 와 Durability , Isolation 을 보장합니다.
System Crash 발생 시, DBMS는 기록된 로그에 Redo 와 Undo 를 수행하여 원자성을 보장하고,
해당 연산 결과를 Stable Storage (ex. HDD) 에 저장하여 Durability 를 보장합니다.
또한, 여러 방식의 Storage Structure를 통해, Durability와 Atomicity를 보장합니다.
RAID (Redundant Array of Inexpensive Disks)
RAID는 이름 그대로, 값 싼 디스크들의 중복 배열 입니다.
값 싼 디스크는 말 그대로 HDD가 될 수 있겠습니다. 여러개의 디스크를 배열해 속도, 안정성, 효율성, 가용성 등의 증대를 위해 사용합니다.
RAID 0 : 성능
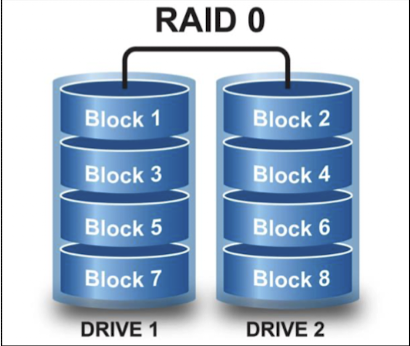
- 모든 드라이브에 디스크 스트라이핑(Striping) 을 제공
- 데이터 중복성을 제공하지 않지만, 최적의 성능을 제공
디스크 스트라이핑은 줄무늬 처럼 블록의 순서를 선형적으로 배치하는 것이 아닌, 라운드 로빈 방식으로 배치하는 방법입니다. 해당 방법을 사용하면, 프로세서가 하나의 디스크에서 데이터를 읽는 것 보다, 이론상 2배 증가된 속도로 데이터를 읽을 수 있습니다.
하지만 보시다시피, Redundant 는 존재하지 않아, 데이터의 중복은 발생하지 않고, 이는 Durability 보다는 성능 효율에 중점이 맞춰진 구조임을 알 수 있습니다.
RAID 1 : 데이터 보호

- Mirroring mode → 용량을 절반으로 사용 (복제본 생성)
- 절반은 데이터 보관에 이용되고, 나머지 반은 사본 복제에 이용
RAID 1은, 그림과 같이 저장소의 공간을 절반만 사용합니다. 남은 절반은 데이터의 복제를 위한 저장소로 사용됩니다. 따라서 안정성이 더 보장되는 장점이 존재합니다.
RAID 5: 데이터 보호 및 속도
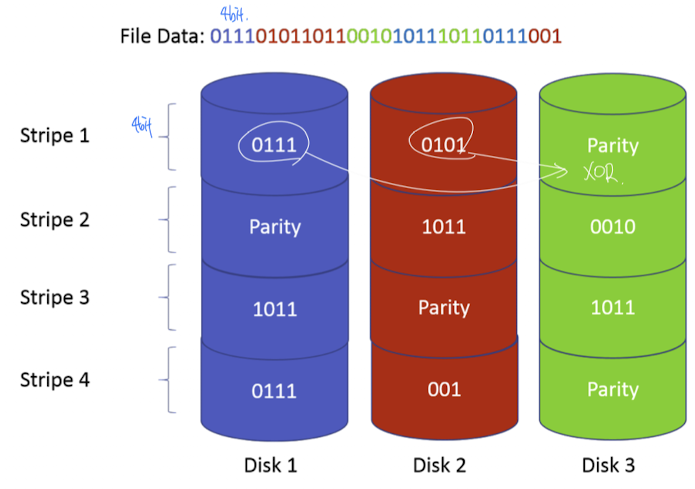
- 드라이브가 3개 이상인 시스템의 경우에 권장
- 모든 드라이브에 걸쳐 데이터를 스트라이핑 함으로써 성능을 높임
- 각 드라이브의 일부를 내고장성에 할애하고, 나머지 부분은 데이터 저장 공간으로 남겨둠으로써 데이터 보호 성능을 최대화
RAID 5 는 드라이브가 3개 이상인 시스템에서 주로 활용합니다. 이전 0, 1 과 다르게 데이터의 복구를 위한 Pairity Bit가 존재합니다.
Pairity Bit는 XOR 연산자로서, 나머지 두 디스크의 데이터가 유실되거나, 의도치 않게 변경되었을 때 Parity Bit을 이용해 복구가 가능합니다.
( Paritiy bit 가 1이라는 것은, 두 비트 의 값이 서로 다르다는 것을 의미하기 때문에 유추가 가능합니다. 0일 경우는 두 비트의 값이 같음을 의미합니다. )
데이터를 스트라이핑하고, Parity bit 도 Striping 함으로서, 데이터 보호 성능을 최대화 하였습니다.
RAID 5 단계는 주로 서버 환경에서 주로 사용됩니다.
RAID 10: 높은 안정성 및 성능

- RAID 1 + 0 → RAID 1 세그먼트를 스트라이핑 하여 매우 높은 I/O 성능을 제공 (용량은 50%)
- 최대 성능 및 높은 내결함성이 중요한 업무 ( ex : DBMS ) 에 사용하는 것이 유리함.
10 단계의 RAID 는 RAID 1 과 RAID 0 이 합쳐진 형태입니다. 데이터를 스트라이핑 하여 속도를 향상하고,
해당 데이터들을 복제하여 내구성까지 보장하는 RAID 단계입니다. 해당 단계는 대부분의 DBMS가 사용하는 방식입니다.
이러한 데이터 구조 위에서 트랜잭션이 durable 하기 위해선, 변경 사항이 stable storage 에 저장되어야 합니다. 비슷하게 atomic 하기 위해선, 값이 변경되기 전에 값을 변경한다는 로그가 먼저 stable storage 에 기록되어야 합니다. 그래야 system crash 등 failure 발생 시 Recovery가 가능합니다.

트랜잭션이 중단된다면 해당 트랜잭션은 Roll back 되어야 합니다. 이 부분은 DBMS의 Recovery scheme 이 담당합니다. 보통 stable storage 에 저장된 log 을 통해 판단합니다.

또한, 트랜잭션이 한번 성공적으로 Commit 되었다면, 절대로 그 이전 상태로 되돌릴 수 없습니다.
상태를 변경하고 싶다면, 오로지 수행한 트랜잭션에 상충하는 트랜잭션을 진행함으로써 상태를 복구해야 합니다.
간단히 말하자면, 100만원 송금을 한번 진행 한 이상, 다시 무를 수 없다는 의미가 됩니다.
상태를 복구하려면 ( 100만원을 다시 얻으려면 ) 입금 받은 사람이 다시 100만원을 송금해주는 수 밖에 없습니다.
Transaction State
- 트랜잭션의 상태

- Active - 초기상태
- Partially Committed - 마지막 명령문까지 실행된 상태
- Failed - 보통 연산이 더이상 진행될 수 없는 상태
- Aborted - 트랜잭션이 롤백된 상태 .
- 진행할 수 있는 연산
- 트랜잭션 재수행 (redo)
- 트랜잭션 종료
- Committed - 트랜잭션이 성공적으로 완료된 상태

위 그래프의 Committed 과 Aborted 는, 작업의 실패와 성공 여부에 관계 없이 트랜잭션이 종료된 상태입니다.
방향 그래프에서 유추 가능하듯이, 이전 상태로 되돌아 갈 수 없습니다.
트랜잭션의 병렬성
현대의 CPU architecture 는, multicore processor 체계를 가지고 있습니다. Multiprogramming 을 통해 동시성을 확보하였고, Multitasking 을 통해 병렬성을 확보한 형태를 가지고 있습니다.
즉, 여러 프로세서에서 동일한 작업을 실행하게 된다면, 다음과 같은 이점을 갖습니다.
- 향상된 프로세서와 디스크 Utilization
- 평균 응답 시간 감소 ( 작업 처리 속도 향상 )
DBMS도 이러한 이유에서 멀티 태스킹, 병렬 처리를 지원합니다.

하지만 고전적인 동시성 문제에서 발생하는 동기화 문제가 있습니다. 따라서 DBMS에도 스레드 락과 비슷한 포지션의 잠금을 이용하여 동기화 문제를 해결합니다. (Isolation)
Concurrency Control Schemes - 동시성 제어 스키마는 Isolation을 구현하기 위한 매커니즘입니다.
동시적인 트랜잭션 사이의 상호작용을 관리하여 서로의 일관성을 파괴하는 행위를 방지합니다.
스케쥴

스케줄은 여러 트랜잭션의 연산을 어떤 순서로 실행할 것인지를 정의한 것을 의미합니다. 즉, 동시에 실행되는 여러 트랜잭션들의 연산 순서를 나열한 것이 스케줄이라고 할 수 있습니다. DBMS는 스케줄을 통해 동시성과 일관성을 보장합니다.
위에서 보았듯이, 트랜잭션이 정상적으로 수행되어 종료될 경우 commit 메세지를, 모종의 이유로 중단되었고, 정상적으로 종료될 경우 abort 메세지를 마지막 구문에 작성한다고 가정합니다.
예시) Schedule 1

다음과 같은 두 트랜잭션, T1 과 T2가 존재한다고 가정하겠습니다.
트랜잭션의 수행 순서를 본다면 T1 → T2 가 실행되는 구조입니다. 내용을 살펴보면
A의 값을 읽고, A-=50 후 A에 작성, B를 읽고 B+=50, B에 작성 후 커밋합니다.(종료)
다음은 T2입니다. A의 값을 읽고, temp 에 A의 10%를 저장, A의 값에서 10%를 차감,
A에 반영합니다. 다음 B를 읽고 B에 A의 10%를 추가, B에 반영 후 commit 합니다.
위 작업으로 보아 T1은 A→B가 50불을 전송, T2는 A→B로 자신의 10%를 송금하는 트랜잭션인 것 같습니다.
위 스케줄은 T1이 실행되고 T2가 실행되는 방식으로, 순서가 보장되는 Serial Schedule 입니다.
그렇다면 질문입니다.
T1 → T2 의 실행이 옳을까요 , T2 → T1 의 실행이 옳을까요 ?
정답은 둘 다 옳습니다. 각 트랜잭션은 순서가 상관 없이 독립적인 연산이어야 합니다.
만약 두 트랜잭션에 순서가 있어야 한다면, 그 트랜잭션은 잘못된 트랜잭션입니다.
애초에 묶여있어야 하는 트랜잭션을 억지로 분리해놓은 모습이 됩니다.
예시) Schedule 2

그 반대도 가능합니다.
예시) Schedule 3

다음 예시는 모양이 조금 변경되었습니다. T1 과T2가 이전에 정의되었으니 한번 같이 보며 비교해 보면 좋을 것 같습니다.
위 트랜잭션은 하는 일은 T1과 동일합니다. 이를 T1과 Equivalent 하다고 합니다.
하지만 한 트랜잭션 사이에, 다른 트랜잭션이 포함됩니다.
즉, 순차적이지 않습니다. 하지만, 이 트랜잭션은 스케쥴 1과 하는 일이 동일합니다.
예시) Schedule 4

다음 스케줄은 조금 다른 형태입니다. Serial 하지 않은 스케줄에 A가 값을 write 하기 전에, T2가 A 값을 읽고 변경 후 작성하고 있습니다.
또한 T2가 B값을 미리 읽었지만, T1이 B값을 변경하고 작성합니다. 그 이후에 T2는 B값을 반영합니다.
이와 같이, 동일한 자원에 대해 동시에 접근하여 값을 변경하게 된다면, Inconsistent한 State 가 발생합니다.
해당 개념에 대해서 같이 알아보겠습니다.
Transaction Serializability
시작에 앞서, 트랜잭션 자체에는 기본적인 오류가 없음을 가정하고 설명하겠습니다. 각 트랜잭션은 동일성을 보장하며, 트랜잭션 집합의 순차적인 실행은 consistency 를 유지 할 것입니다.
만약 스케줄이 Serializable (직렬 가능) 하다면, 그 트랜잭션은 순차적인 스케줄과 Equivalent 합니다.
Schedule Equivalence 에는 두가지 형태가 있습니다.
- Conflict Serializability
- View Serializability
이 중에서, Conflict Serializability 를 통해 설명하겠습니다.
직렬 가능 ?
직렬 가능하다는 것은 무슨 뜻 일까요? 다음 트랜잭션을 살펴보겠습니다.

트랜잭션을 어떠한 순서대로 실행해도, 문제되는 부분은 없습니다. T1→T2, T2→T1 로 실행해도 a의 값은 동일하지 않지만, 위에서 우리는 트랜잭션 자체에는 문제가 없음을 가정했기 때문에, 두 트랜잭션 모두 올바른 트랜잭션 입니다.
정리하자면, 트랜잭션을 하나씩 차례로 수행했을 때, 나올 수 있는 모든 결과는 올바른 것이라고 할 수 있습니다.
Conflicting Instructions
Ii와 Ij가 트랜잭션 Ti 와 Tj의 연산이라고 가정하겠습니다. 연산 Ii와 Ij가 똑같은 데이터 Q에 접근하는데,
둘 중 하나 이상이 Q의 값을 변경하게 된다면, Conflict 가 발생합니다.
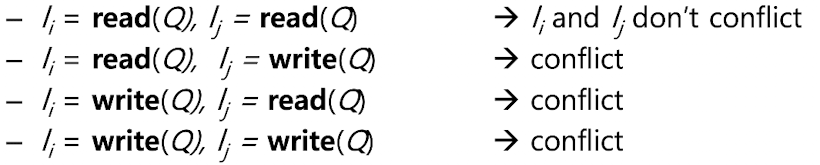
그렇다면 위에서 설명한 Inconsistence 한 스케줄이 설명됩니다.

첫번째 트랜잭션은 Serializable 하지 않고, Conflict가 발생합니다. (write, read)
그 아래에도 (write, read) 를 하고 있지만, 접근하는 자원이 다르기 때문에, (A,B) Conflict 가 일어나지 않습니다.
Conflict가 없는 명령어들은 서로의 순서 변경이 가능합니다.
오른쪽 예시는 read(B)와 write(A)의 시간적 순서를 변경한 모습입니다.
Conflict Serializability
위에서 Conflict가 일어나지 않는 명령어들은 서로의 순서 변경이 가능함을 알 수 있었습니다.
DBMS에서는 스케줄 S의 conflict 가 발생하지 않는 연산의 순서를 변경해 다른 스케줄 S’ 로 순서 변경이 가능하다면,
‘S와 S’는 Conflict Equivalent 하다’ 고 합니다.
또한, 스케줄 S가 Serial Schedule (순차적인 스케줄)과 Conflict Equivalent 하다면, S를 Conflict Serializable 하다고 합니다.
저는 이 부분의 정의가 굉장히 헷갈렸습니다. 제 나름대로의 정리를 적어드릴 테니, 이해에 도움이 되었으면 좋겠습니다.
- Serializable : 직렬 가능한, 여러 트랜잭션을 실행해도 순차 실행과 동일한 결과
- Conflict Equivalent : 스케줄이 다른 스케줄 S로 Conflict 없이 변환될 수 있다면 Conflict Equivalent
- Conflict Serializable : Conflict Equivalent 한 스케줄이 Serializable 한 스케줄과 Conflict Equivalent 하다면, Conflict Serializable 하다.
해당 개념을 통해 Schedule 3을 다시 보겠습니다.
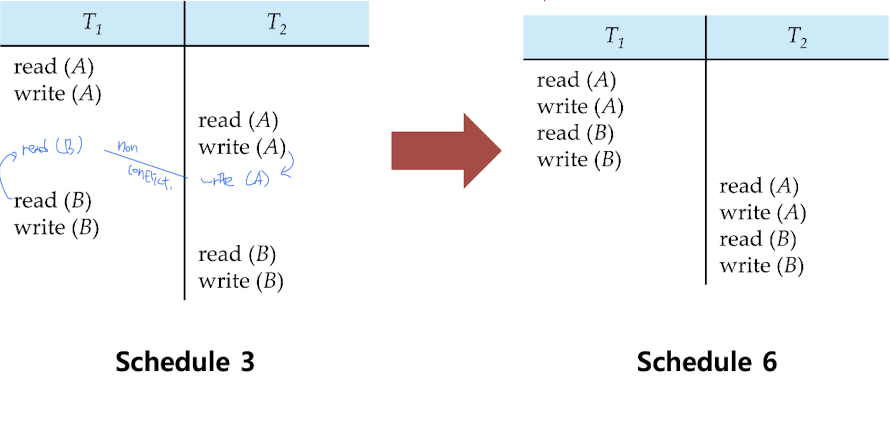
스케줄 3의 Conflict 가 일어나지 않는 연산의 순서를 바꾸면, 다음과 같이 스케줄 6과 같은 형태가 만들어집니다.
스케줄 6은 순차 실행되는 Serializable 한 스케줄입니다.
그렇다면 스케줄 3은 스케줄 6과 conflict equivalent하고, 또한 스케줄 6은 Serializable 한 스케줄이므로 , 스케줄 3은 Conflict Serializable 한 스케줄이 되겠습니다.
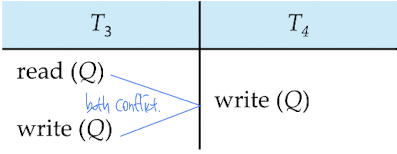
하지만 다음과 같이 공유 자원에 대한 접근은 Conflit 가 발생하고, 순서 교환이 불가능합니다.
따라서 Conflict Serializable 하지 않습니다.
아래의 스케줄 <T1,T5>는 같은 결과를 만들어냅니다. 하지만 Conflict가 발생하기 때문에, Conflict Equivalent하지는 않습니다.

Testing for Serializability
그럼 어떻게 스케줄이 Serializability 를 보장하는지 알 수 있을까요?
바로 Precedence graph (선형 그래프)를 통해 테스트를 진행할 수 있습니다.

다음 두 그래프는 순서가 보장되어 있습니다. 방향 그래프이기 때문에, T1 이후 T2가 실행되거나, T2 이후에 T1 이 실행되어야 함을 알 수 있습니다.
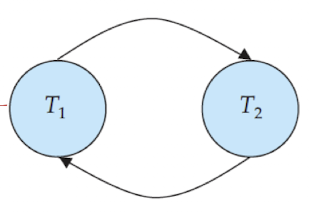
하지만 다음과 같이 사이클이 발생한다면 , DBMS는 어떤 트랜잭션을 먼저 수행해야 할 지 순서를 정하지 못하게 되고, 이는 Conflict Serializable 하지 못함을 의미합니다.
정리하자면, 선행 그래프를 그려보았을 때, 사이클이 존재하지 않는 경우에만 스케줄은 Conflict Serializable 하다고 할 수 있겠습니다.
만약 그래프가 사이클이 없다면, Serializability 순서는 위상 정렬에 의해서 한 순차적으로 정렬될 수 있습니다.

다음과 같이 선행하는 트랜잭션이 없는 트랜잭션부터 분리하여 선형적인 순서로 도출할 수 있습니다.
Recoverable Schedules
Recoverable Schedule( 회복 가능한 스케줄 ) 은 만약 트랜잭션 Tj 가 이전에 Ti에 의해 쓰여진 데이터를 읽는다면, Ti의 커밋 연산은 반드시 Tj의 연산이 수행되기 전에 작성되어야 함을 의미합니다 .
즉, Ti가 Commit 하는 시점은, Tj 가 commit 하기 전이어야 함을 의미하고, 이는 이 전에 값을 변경한 Ti가 먼저 커밋해야 한다고 정의할 수 있습니다.

다음과 같은 상황은 Not Recoverable 한 상황입니다. T9가 커밋을 먼저 진행하였기 때문에,
T8이 Abort 되는 상황일 경우, T9는 이미 커밋되었기 때문에, Inconsistent state가 노출되게 됩니다.
Cascading Rollbacks
Cascading Rollback 이란, 단일 트랜잭션의 실패가 연속된 트랜잭션의 롤백으로 이어지는 경우를 뜻합니다.
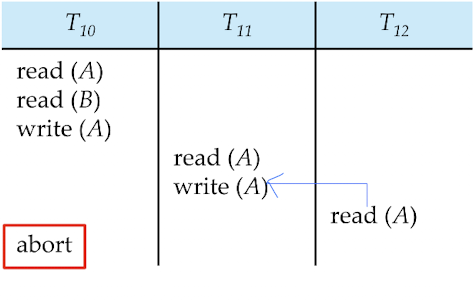
만약 T10이 commit 전에 중단된다면, 변경된 A의 값에 접근하고 , 수정하는 T11, T12 또한 중단되어야 합니다.
이를 Cascading Rollback 이라 부르며, 이는 시스템 성능에 상당히 큰 부하를 가져옵니다.
이를 방지하기 위해, Cascadeless Schedules가 존재합니다.
Cascadeless Schedules
트랜잭션 Tj는 Ti가 변경한 데이터를 읽습니다. 하지만 이번에는 읽기 전에 Ti 가 Commit 한 후에 데이터를 읽도록 합니다. 그러면 이미 commit 되었기 때문에, T11이나 T12가 잘못되어도 해당 트랜잭션만 롤백하면 됩니다.
즉, Cascading Rollback이 일어나지 않습니다.
또한, 모든 Cascadeless schedule은 recoverable 합니다.
Transaction Isolation Levels
다음은 Consistency를 위한 고립성 단계에 대한 설명입니다.
위 과정에서 Serial 한 스케줄과 consistency를 유지하는 방법에 대하여 배웠습니다.
그렇다면 해당 과정이 무조건 필요한 절차일까요 ? 이 또한 Trade-off 가 작용합니다.
강한 고립성과 Serial한 스케줄은 병렬 처리의 관점에서는 안정성을 제공하지만, 그러한 작업들이 필요하지 않은 경우에는 해당 절차들을 느슨하게 가져가는 경우가 있습니다.
- Read Only 트랜잭션
- 쿼리 최적화를 위해 계산된 데이터베이스 통계
이러한 트랜잭션들은 serializable 하지 않아도 문제가 잘 발생하지 않습니다. 이러한 각자의 환경에 맞춰서
몇몇 application 들은 not serializable 한 스케줄을 허용하고, 약한 레벨의 consistency를 가집니다.
따라서 DBMS에는 고립성 단계가 존재합니다. 같이 살펴보겠습니다.
Levels of Consistency in SQL-92
- Serializable : 기본값
- Repeatable read : 오직 Commit 된 레코드만 읽을 수 있습니다. 같은 레코드를 반복적으로 읽어도 반드시 동일한 값을 반환합니다. 하지만, 트랜잭션은 serializable 하지 않을 수 있습니다. 트랜잭션 도중 삽입된 새로운 값은 발견할 수도 있고, 발견하지 못할 수도 있습니다.
- Read committed : 오직 commit 된 레코드만 읽을 수 있지만, 반복해서 읽을 경우 다른 값을 반환할 수 있습니다. (하지만 commit 된 값입니다. )
- Read Uncommitted : 커밋되지 않은 레코드 또한 읽을 수 있습니다.

높은 수준의 Isolation Level일 수록 Concurrency는 떨어지지만 ( 성능 )
더 높은 수준의 Consistency를 보장합니다. ( 정확성 )
Dirty Read
Commit 되지 않은 데이터 변경을 읽을 수 있습니다.
- 문제점:
- Serializable 하지 않은 결과가 반환될 수 있습니다.
- 롤백이 일어날 경우 cascading Rollback이 일어납니다.

트랜잭션들은 커밋되지 않았지만, 커밋되지 않은 값들에 이리저리 접근하며 값을 변경하고 있는 모습입니다.
이 경우 T1이 롤백될 경우, T2, T3 또한 롤백됩니다.
Isolation Level : Read Uncommitted

Read Uncommitted 단계에서는 커밋되지 않은 데이터를 읽을 수 있습니다 . → Dirty Read를 허용합니다.
따라서 두 트랜잭션은 동시에 실행 가능하고, Serializable 하지 않은 스케줄이 발생할 수 있습니다.
T1이 price의 값을 변경하는 도중에, T2가 실행이 가능합니다. 테이블의 일부 값만 바뀔 수도 있고 결과를 보장할 수 없기 때문에 , serializable 하지 않습니다.
Isolation Level : Read Committed

Read Commited 단계는 Dirty Read를 허용하지 않습니다.
- T1의 수행 중간에 T2가 수행되지 않음을 의미합니다.
Nonrepeatable Read :
- repeatable 하지 않은 Read가 발생할 수 있습니다.
- T2:S1 → T1 → T2:S2 의 순서로 실행이 가능합니다.
- 따라서 동일한 select 문이지만, 서로 다른 결과가 발생할 수 있습니다.
Commit 된 데이터만 읽을 수 있습니다. transaction 완료되기 이전에 시작 상태의 데이터도, 이전 트랜잭션에 의해 commit 된 데이터입니다. 트랜잭션 중 데이터를 읽을 때, 다른 트랜잭션에 의해 데이터가 변경되고 commit 된 경우에도 그 값을 읽을 수 있습니다.
따라서 T2의 S1 실행 도중에, T1이 실행이 가능하고, T1에 의해 값이 변경된 이후 T2:S2의 실행이 가능합니다.
이는 Serializable 하지 않은 스케줄이 발생 가능함을 의미합니다.
Isolation Level : Repeatable Read

- 반복하여 읽어도 동일한 값을 반환합니다. → Dirty Read를 허용하지 않습니다.
- Repeatable Read를 보장합니다 :
- 이미 읽은 데이터는 다시 읽어도 동일한 값이 되도록 보장합니다.
- Serializable 하지 않은 Schedule이 발생 가능합니다.

위 트랜잭션 예시를 본다면 문제가 없는 것 같습니다. 어떤 부분에서 Serializable 하지 않을까요 ?
Phantom Read Problem 발생 가능
Repeatable read 에서는 Insert/Update/Delete 연산 에서 Phamtom read problem이 발생할 수 있습니다.
한번 읽었던 튜플의 값은 변경되지 않지만, 새로운 튜플이 추가될 수는 있습니다. ( 읽었던 튜플이 아니기 때문입니다.)
T1에 의하여 추가된 튜플은 이전에 존재하지 않았으므로, T2:S1 → T1 → T2:S2 순서로 실행이 가능합니다.
→ 동일한 결과가 나오지 않을 수 있습니다.
Isolation Level : Serializable
가장 높은 단계의 고립 레벨입니다.
- 항상 Serializable 한 결과 보장
- No dirty read
- Repeatable Read
- No phantom Read
Isolation Level 요약

하지만 실제 DBMS 별로 제공하는 Transaction Level 과 Default 가 다르기 때문에, 해당 개념을 바탕으로 공식 문서를 참고하는 것을 추천합니다.
이렇게 DBMS의 트랜잭션에 대하여 알아보았습니다. 다음 포스팅에서는 동시성을 관리하는 Concurrency Control Scheme 에 대하여 알아보겠습니다.
틀린 부분이나 질문 있으시면 댓글 달아주시면 감사하겠습니다 !
'CS > 데이터베이스' 카테고리의 다른 글
| Query Optimization (1) | 2023.12.21 |
|---|---|
| Materialization 과 Pipelining (0) | 2023.10.30 |
| Query Processing (1) | 2023.10.28 |