2023. 11. 3. 20:56ㆍServer/소켓프로그래밍
소켓은 특정한 파이프의 끝, 파이프 이음쇠 또는 위생 기구를 수용하기 위해 확장한 것으로, 또 다른 파이프의 끝이나 파이프 이음쇠을 가리킨다. 또한 소켓(socket)은 통신선 또는 전기선, 전구 따위를 끼워 넣어 연결선과 접속하게 하는 연결기구를 가리킨다.
일상생활에서 소켓은 자주 접할 수 있습니다. 콘센트 플러그도 소켓, 전구의 소켓을 갈아끼운다. 등의 표현을 심심찮게 접할 수 있습니다.
위의 정의와 같이 소켓은 무언가 연결하기 위한 기구를 뜻합니다.
컴퓨터 언어에서도 다음과 같이 일상 생활의 용어를 종종 차용하곤 합니다. 그렇다면 소켓 프로그래밍은 무엇을 위한 프로그래밍일까요?

컴퓨터 네트워크는 layered architecture 를 사용하고 있습니다. 레퍼런스를 위한 OSI 7 모델이 위와 같이 존재하고,
Sender 는 데이터를 보내기 위해 각 층마다 헤더를 붙여서 전송합니다 (ex. eth 프레임, IP 헤더 등). 층과 역할에 따라 다른 이름으로 헤더들은 존재합니다. 즉 헤더는 계층 프로토콜의 행동을 특정한다고 할 수 있습니다.
현실에서 물건 배송을 예로 들어보자면,
작은 물체를 상자에 넣고 그 상자를 더 큰 상자에 넣고, 더 큰 상자에 넣는 것 처럼 보낼 물품을 포장합니다.
물건을 전송하는 택배 기사님이 택배를 배송하면 받는 이는 큰 택배에서 작은 택배로 언박싱을 진행합니다.
언박싱을 진행하며 반품요구서가 들어 있을 수도 있고, 인보이스가 들어 있을 수도 있습니다. 하지만 실제 내용물은 작은 더 작은 박스를 열어봐야 알 수 있는 것 처럼, 각 계층마다 역할이 정해져 있습니다.
소켓 프로그래밍은 이렇게 네트워크를 이용하여 데이터를 전달할 때 데이터를 보내고 받을 수 있도록 하는 '연결 기구'의 역할을 합니다.
현재 사용하는 소켓 라이브러리는 1980년대 Berkeley socket 을 근간으로 하고 있습니다.
거의 모든 OS가 해당 라이브러리를 API로 구현하고 있습니다. C언어로 작성되어 있고, 실제 언어별로 지원되는 문서들을 본다면 비슷한 형태로 작성되어 있는 모습을 볼 수 있습니다.
각설하고 소켓의 생성부터 알아보겠습니다.
소켓 생성
$man socket
**NAME**
**socket** – create an endpoint for communication
**SYNOPSIS**
**#include** **<sys/socket.h>**
int
**socket**(int domain, int type, int protocol);
**DESCRIPTION**
**socket**() creates an endpoint for communication and returns a descriptor.
man page 내용입니다.
#include <sys/socket.h> 를 include 하고,
도메인, type,protocol 을 인자로 넘겨주게 됩니다.
이렇게 말하면 감이 잘 안잡히니, UDP 소켓 생성 예시를 보겠습니다.
#include <arpa/inet.h>
#include <sys/socket.h>
int s = socket(AF\_INET,SOCK\_DGRAM, IPPROTO\_UDP); //UDP 소켓 생성
cout<< s <<endl; 코드를 실행한다면 '3' 이 출력됩니다.
낯선 구조입니다. 소켓이 int 형? 하고 의문이 들 수 있습니다.
현대에서는 OOP가 활성화 되어
Socket socket = new Socket(...)
와 같은 형식으로 사용했겠지만, 당시 Berkeley Socket이 개발될 시기는 아쉽게도 OOP가 적용되지 않았습니다.
그렇다면 int s = socket(...) 를 실행 한 후 s가 소켓인지 알 수 있을까요?
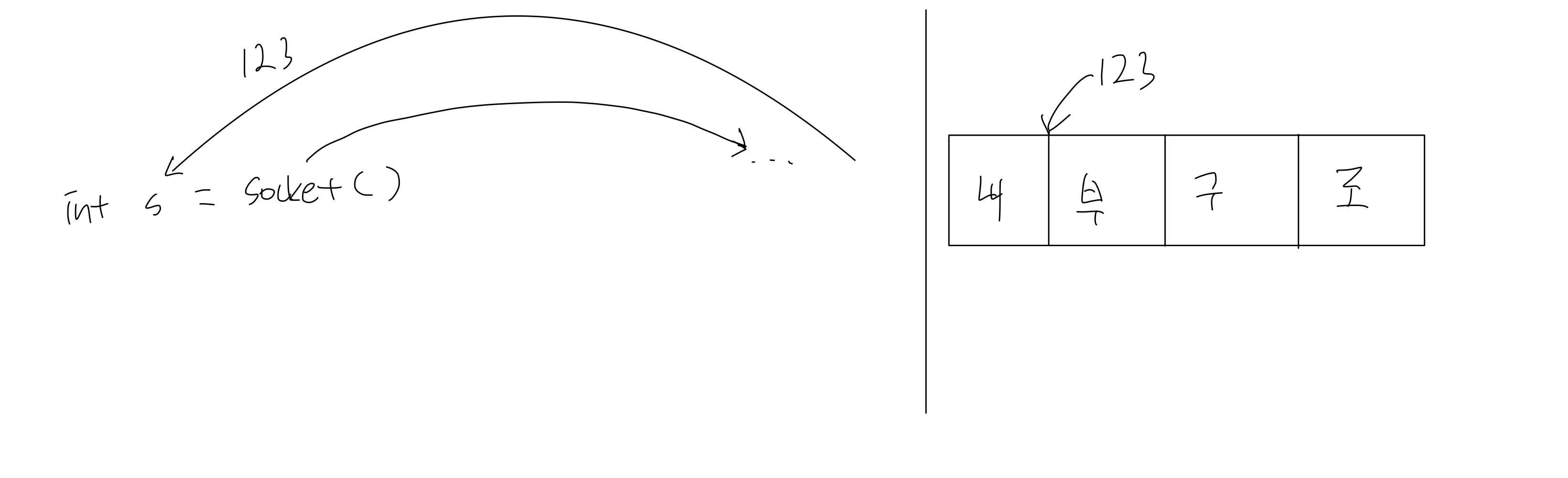
소켓 함수를 실행 시, 내부에서 함수가 실행되고 정수 값을 반환받습니다. 이는 곧 socket Descriptor 의 Opaque(불투명)한 Handle 이 됩니다.
즉, 우리는 이 숫자가 뭔지는 정확히 모르지만, 시스템 내부 자료구조에서 내가 만든 소켓을 가리키는 handle이 됩니다.
조금 더 첨부하자면, linux 는 모든 것들을 파일 단위로 처리합니다. socket 또한 파일 단위로 취급되는데, 0,1,2 번의 파일들은 이미
표준 입력, 표준 출력, 표준 에러의 파일 디스크립터가 자리하고 있기 때문에, 우리는 그 다음 순번인 3번 파일 디스크립터를 배정받아
소켓을 사용하게 됩니다.
따라서 직접 사용할 때에는, 이 opaque 한 handle을 매개변수로 넘겨주어 사용하게 됩니다. 이는 해당 소켓 자체를 넘겨주는 것이 아니라, 해당 소켓 지칭을 위한 이름표를 넘겨주는 상황입니다.
Remind : TCP vs UDP
앞에서 소켓 디스크립터의 원리를 알아보았습니다. 그렇다면 소켓 프로그래밍에서는 TCP , UDP 관련된 소켓만 다룰 수 있을까요?
-> 정답은 아니오 입니다.
네트워크에는 다양한 레이어가 존재합니다. 소켓은 ‘내가 커스텀 하려는 계층의 내용만 직접 채우고, 나머지 계층의 헤더는 알아서 채워주는 라이브러리’ 의 개념으로 생각해야 합니다. 즉, L2의 소켓도 생성할 수 있습니다.
Q. 만약 L3 소켓을 생성한다는 것은 무슨 의미일까요?
A. L2 까지의 헤더는 소켓 라이브러리가 채워주고, L3 부터는 사용자(개발자) 가 직접 내용물을 채워넣어야 한다는 것을 의미합니다.
그렇다면 소켓 프로그래밍에서 많이 사용되는 TCP/UDP 의 차이점에 대해 간단하게 알아보겠습니다.
TCP 는 stateful 합니다.
-> 특정 상대와의 통신과 관련된 상태값들을 기억하고 header 로 전송합니다.
-> 상태를 기억해야 하므로, 서로 연결하는 행위를 거치게 되며, 그 이후는 별도 목적지 지정 없이 연결된 pipe 를 이용해 통신합니다.
UDP 는 stateless 합니다.
관리하는 상태 값도 없고, header로 부가적으로 전송하는 정보도 없습니다.( cheksum 제외)
따라서 비 연결 지향적인 프로토콜이며, 정해놓은 pipe 가 없기 때문에, 전송시마다 목적지를 기재해야 합니다.
Bind 란 ?
TCP / UDP 네트워크 환경에서는 IP/port 를 이용하여 내 데이터를 어디로 보낼지 결정합니다. 그 말은 곧 데이터를 어디론가 보내기 위해서는 ip 와 port 번호가 필요하다는 것을 의미합니다. 다른 말로, 서버는 네트워크에서 항상 client 들이 찾을 수 있는 위치에 있어야 합니다. (계속 주소가 바뀌는 서버를 생각해 보시면 되겠습니다..)
그렇다면 서버는 클라이언트의 지속적인 연결을 받기 위해서 고정된 ip와 port 가 있어야 하겠습니다. 그래서 필요한 것이 bind 입니다.
bind 는 ‘묶다’라는 뜻 그대로 ‘소켓을 내가 지정한 port와 ip 로 묶는다’ 라는 뜻입니다.
Q. 그렇다면 클라이언트 측도 bind가 가능할까요?
A. 그렇습니다. 계속 한 자리만을 고집하는 손님처럼, 클라이언트도 bind가 가능합니다. 하지만 서버 측은 필수고, 클라이언트 측은 선택적인 사항이라는 점이 차이가 되겠습니다.
다음 포스팅에서는 UDP/TCP 소켓프로그래밍의 절차에 대해 알아보도록 하겠습니다.
'Server > 소켓프로그래밍' 카테고리의 다른 글
| Socket - TCP & UDP (2) | 2023.11.26 |
|---|